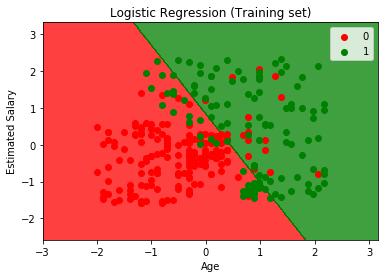
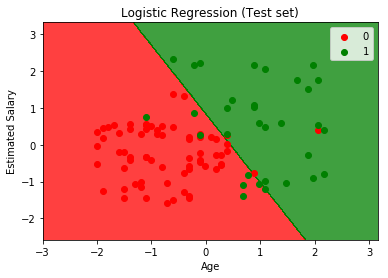
로지스틱 회귀

데이터셋 | 소셜 네트워크
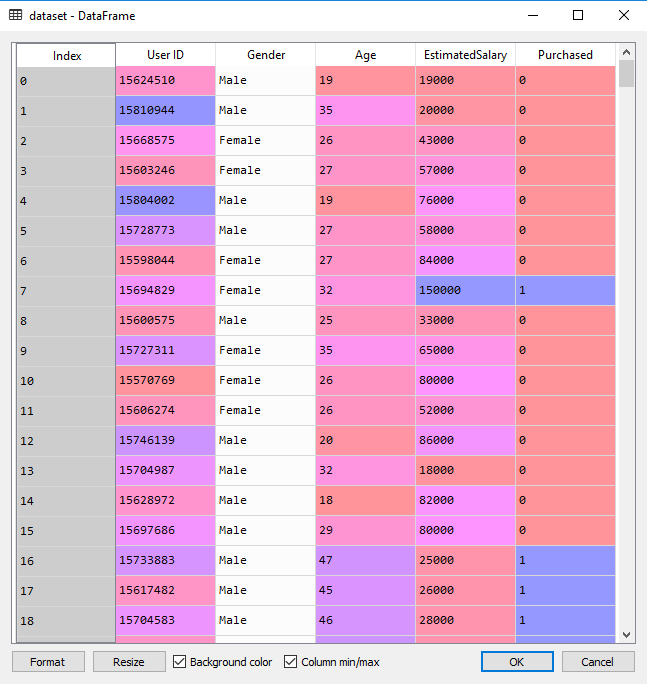
이 데이터셋에는 소셜 네트워크 사용자 정보가 포함되어 있습니다. 이 정보는 사용자 ID, 성별, 나이 및 예상 급여입니다. 한 자동차 회사가 새로운 고급 SUV를 출시했습니다. 그리고 우리는 이 소셜 네트워크 사용자 중 누가 이 새로운 SUV를 구매할 것인지 확인하려고 합니다. 그리고 여기 마지막 열은 사용자가 이 SUV를 구매했는지 여부를 나타냅니다. 우리는 두 가지 변수, 즉 나이와 예상 급여를 기반으로 사용자가 SUV를 구매할지 여부를 예측하는 모델을 구축할 것입니다. 따라서 우리의 특징 행렬은 이 두 열만 해당됩니다. 우리는 사용자의 나이와 예상 급여, 그리고 SUV 구매 결정(예 또는 아니오) 사이의 상관 관계를 찾고 싶습니다.
1단계 | 데이터 전처리
라이브러리 가져오기
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
데이터셋 가져오기
여기에서 데이터셋을 가져오세요.
dataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values # 독립 변수 (나이, 예상 급여)
y = dataset.iloc[:, 4].values # 종속 변수 (구매 여부)
데이터셋을 훈련 세트와 테스트 세트로 분할
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0) # 75% 훈련, 25% 테스트
특징 스케일링
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train) # 훈련 세트에 스케일러 학습 및 적용
X_test = sc.transform(X_test) # 테스트 세트에 학습된 스케일러 적용
2단계 | 로지스틱 회귀 모델
이 작업에 사용할 라이브러리는 선형 모델 라이브러리이며 로지스틱 회귀가 선형 분류기이기 때문에 선형이라고 불립니다. 즉, 여기서는 2차원이므로 두 사용자 범주는 직선으로 구분됩니다. 그런 다음 로지스틱 회귀 클래스를 가져옵니다. 다음으로 이 클래스에서 새 객체를 만들 것인데, 이 객체는 훈련 세트에 적합시킬 분류기가 됩니다.
훈련 세트에 로지스틱 회귀 피팅
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression() # random_state는 필요에 따라 추가 가능
classifier.fit(X_train, y_train)
3단계 | 예측
테스트 세트 결과 예측
y_pred = classifier.predict(X_test)
4단계 | 예측 평가
테스트 결과를 예측했으며 이제 로지스틱 회귀 모델이 올바르게 학습하고 이해했는지 평가할 것입니다. 따라서 이 혼동 행렬에는 모델이 세트에서 수행한 올바른 예측과 잘못된 예측이 포함됩니다.
혼동 행렬 만들기
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
시각화